随着大数据技术的快速发展,运维大数据处理及运维服务成为IT行业的热门方向。对于初学者来说,系统性地学习这一领域至关重要。以下是一个循序渐进的学习路径,帮助您从零开始掌握运维大数据处理及运维服务的核心技能。
一、打好基础:掌握运维与大数据核心概念
- 学习Linux操作系统基础:作为运维的基石,熟悉Linux常用命令、文件系统、进程管理和Shell脚本编写是必不可少的。建议从Ubuntu或CentOS入手,通过实践加深理解。
- 了解网络基础:掌握TCP/IP协议、DNS、HTTP等网络知识,理解网络拓扑和故障排查方法。
- 入门大数据概念:学习Hadoop、Spark等开源框架的基本原理,理解分布式存储和计算的概念。了解数据采集、存储、处理和分析的流程。
二、进阶技能:掌握大数据处理工具与运维服务
- 学习大数据生态系统工具:
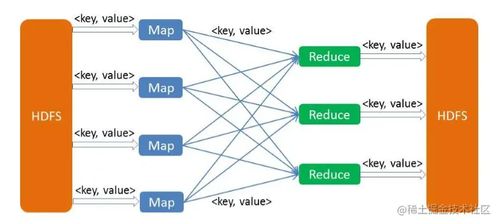
- 熟悉HDFS、YARN、Hive、HBase等Hadoop组件。
- 掌握Spark用于实时数据处理,学习Kafka用于数据流处理。
- 了解数据仓库工具如ClickHouse或数据湖概念。
- 运维服务实践:
- 学习容器化技术,如Docker和Kubernetes,用于部署和管理大数据应用。
- 掌握监控工具(如Prometheus、Grafana)和日志分析工具(如ELK栈),确保系统高可用性。
- 了解自动化运维工具,如Ansible或Terraform,提升效率。
三、实战与项目经验
- 搭建实验环境:在本地或云平台(如AWS、阿里云)上部署小型Hadoop或Spark集群,模拟数据处理任务。
- 参与开源项目或实际案例:通过GitHub等平台贡献代码,或尝试处理公开数据集(如Kaggle数据),锻炼问题解决能力。
- 关注运维服务场景:例如,设计一个数据 pipeline,从数据采集到可视化,并实施监控告警机制。
四、持续学习与社区参与
- 跟进技术动态:大数据和运维技术更新迅速,定期阅读官方文档、技术博客(如Apache官网、Medium)。
- 加入社区:参与论坛(如Stack Overflow)、技术群组或Meetup,与同行交流经验。
- 考取认证:考虑获取相关认证,如Cloudera的CCA或AWS大数据认证,以验证技能。
五、常见挑战与建议
- 挑战:初学者可能面临概念抽象、环境配置复杂等问题。建议从简单项目开始,逐步增加复杂度。
- 学习方法:结合理论与实践,多动手实验;利用在线课程(如Coursera、极客时间)系统学习。
- 职业规划:运维大数据处理涉及多个角色,如数据工程师、运维工程师,可根据兴趣专注某一方向。
学习运维大数据处理及运维服务需要耐心和持续实践。从基础运维技能出发,逐步深入大数据工具链,并通过项目积累经验,您将能够在这一领域稳步成长。记住,实际操作和解决问题的能力是关键,祝您学习顺利!