MapReduce是一种经典的大数据处理编程模型和框架,最初由Google提出,后来在Hadoop生态系统中得到广泛应用。它通过将大规模数据处理任务分解为Map(映射)和Reduce(归约)两个阶段,实现了分布式计算的并行处理。在本文中,我们将详细解析MapReduce的核心原理、工作流程、优势与局限性,并结合实际应用场景进行探讨。
一、MapReduce核心原理
MapReduce模型基于函数式编程思想,将数据处理任务分为两个主要阶段:
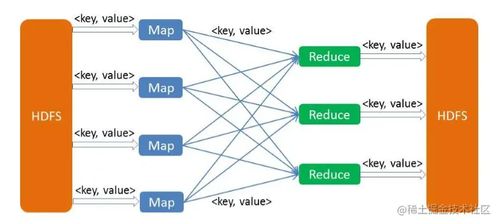
1. Map阶段:输入数据被分割成多个独立块,每个块由一个Map任务处理,生成中间键值对(key-value pairs)。
2. Reduce阶段:中间结果根据键进行分组和聚合,由Reduce任务处理,最终输出结果。
该框架自动处理数据分布、任务调度和容错,开发者只需关注业务逻辑实现。
二、工作流程详解
- 输入分片:数据被分割成固定大小的分片,每个分片分配给一个Map任务。
- Map阶段:每个Map任务处理一个分片,应用用户定义的Map函数,生成中间键值对。
- Shuffle和排序:中间数据根据键排序并分发到相应的Reduce节点。
- Reduce阶段:每个Reduce任务处理一组键,应用用户定义的Reduce函数,聚合结果。
- 输出:最终结果写入分布式文件系统(如HDFS)。
三、MapReduce的优势与局限性
优势:
- 高扩展性:可轻松扩展至数千节点处理PB级数据。
- 容错性:自动处理节点故障,重新执行失败任务。
- 简单编程模型:开发者无需关注底层分布式细节。
局限性:
- 不适合实时处理:批处理模式导致高延迟。
- 中间数据写入磁盘:影响性能,尤其对于迭代计算。
- 复杂性较高任务需多次MapReduce作业。
四、实际应用场景
- 日志分析:处理Web服务器日志,统计访问频率或错误率。
- 搜索引擎:构建倒排索引,用于网页排名。
- 数据挖掘:执行聚类或关联规则挖掘,如购物篮分析。
- 机器学习:训练大规模模型,如协同过滤推荐系统。
五、与联网信息服务的结合
在联网信息服务中,MapReduce可用于:
- 用户行为分析:处理用户交互数据,优化服务推荐。
- 网络监控:分析流量日志,检测异常模式。
- 内容聚合:整合多源数据,生成个性化摘要。
通过集成Hadoop生态系统工具(如Hive或Pig),可进一步提升开发效率。
尽管新兴框架(如Spark)在性能上有所超越,MapReduce作为大数据处理的基石,其思想和架构仍深刻影响着分布式计算领域。对于历史数据批处理和教学理解,它依然具有重要价值。在实际应用中,结合具体需求选择合适的框架是关键。